
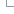
Gene annotation in Ensembl
Gene annotation is the plotting of genes onto genome assemblies, and indexing their genomic coordinates.
Gene annotation provided by Ensembl for human GRCh37 includes automatic annotation, i.e. genome-wide determination of transcripts, and manual curation, i.e. reviewed determination of transcripts on a case-by-case basis.
Ensembl transcripts displayed on our website are products of the Ensembl automatic gene annotation system (a collection of gene annotation pipelines), termed the Ensembl annotation process. All Ensembl transcripts are based on experimental evidence and thus the automated pipeline relies on the mRNAs and protein sequences deposited into public databases from the scientific community. Manually-curated transcripts are produced by the HAVANA group.
An Ensembl gene (with a unique ENSG... ID) includes any spliced transcripts (ENST...) with overlapping coding sequence, with the exception of manually annotated readthrough genes which are annotated as a separate locus. Transcripts from the Ensembl annotation process, the Havana/Vega set and the Consensus Coding Sequence (CCDS project) set may all be clustered into the same gene. Transcripts that belong to the same gene ID may differ in transcription start and end sites, splice events and exons, and can give rise to very different proteins. Transcript clusters with no overlapping coding sequence are annotated as separate genes. Two transcripts may overlap in non-coding sequence (ie intronic sequence or UnTranslated Region (UTR), and be classified under two separate genes. After the Ensembl gene and transcript sequences are defined, the gene and transcript names are assigned.
The image below shows a cartoon of a gene ("GENE") with five transcripts, some coding (red) and non-coding (blue).

The sequence of any gene or transcript shown in Ensembl is the sequence in the underlying genome assembly, where the sequence of any protein is the translated genomic sequence. This is to prevent any mismatch between the genes and the genome. For this reason, sequences of genes, transcripts and proteins in Ensembl may differ from other databases, who may use sequence from other individuals than were used to produce the genome.
Find out more about the different types of gene annotation used by Ensembl, and where we get our data from:
- Automatic annotation of coding genes.
- Automatic annotation of non-coding genes.
- Annotation of immunoglobulin and T-cell receptor genes.
- Automatic annotation using RNA-seq data.
- Manual gene annotation by Havana.
- The Ensembl and Havana merge.
- CCDS.
- Sources of data for gene annotation.
- Gene naming.
- Transcript tags.
- Gene and transcript types.
- External references.